Here, I briefly introduce our work. Some contents are extracted from the accepted version of our paper. For more information please see our paper. Code is available at github.

Highlights
- We are the first to construct dynamic graphs on skeleton sequences that capture discriminative relations between skeletons.
- Relational Adjacency Matrix is proposed to present relational graphs using geometric features and relative attention.
- Proposed Dyadic Relational Graph Convolutional Network achieves state-of-the-art accuracy on three challenging datasets and improvements of 6.63% on NTU-RGB+D and 5.47% on NTU-RGB+D 120 over the baseline model.
- Our methods consistently help advanced models achieve higher accuracy of 1.26% on NTU-RGB+D and 2.86% on NTU-RGB+D 120.
Abstract
Skeleton-based human interaction recognition is a challenging task requiring all abilities to recognize spatial, temporal, and interactive features. These abilities rarely co-exist in existing methods. Graph convolutional network (GCN) based methods fail to extract interactive features. Traditional interaction recognition methods cannot effectively capture spatial features from skeletons. Toward this end, we propose a novel Dyadic Relational Graph Convolutional Network (DR-GCN) for interaction recognition. Specifically, we make four contributions: (i) we design a Relational Adjacency Matrix (RAM) that represents dynamic relational graphs. These graphs are constructed combining both geometric features and relative attention from the two skeleton sequences; (ii) we propose a Dyadic Relational Graph Convolution Block (DR-GCB) that extracts spatial-temporal interactive features; (iii) we stack the proposed DR-GCBs to build DR-GCN and integrate our methods with an advanced model. (iv) Our models achieve state-of-the-art results on SBU and significant improvements on the mutual action sub-datasets of NTU-RGB+D and NTU-RGB+D 120.
Method

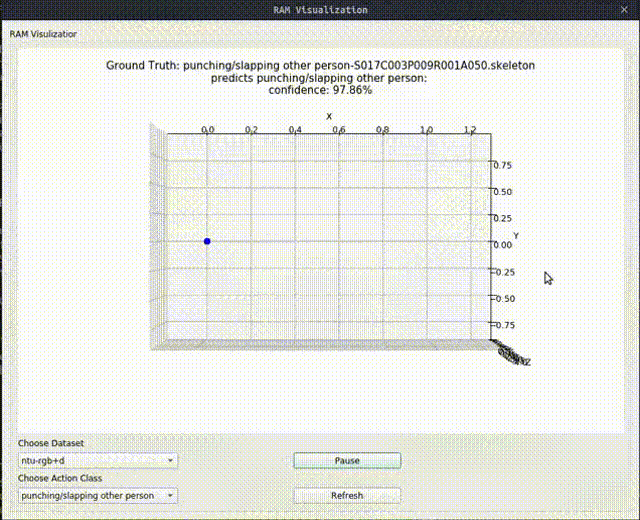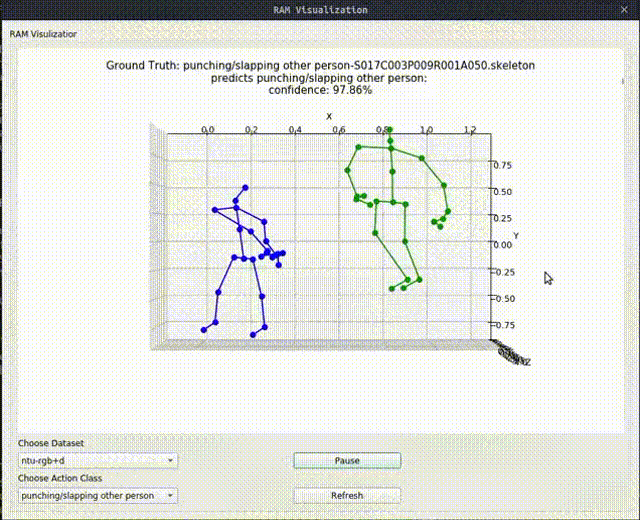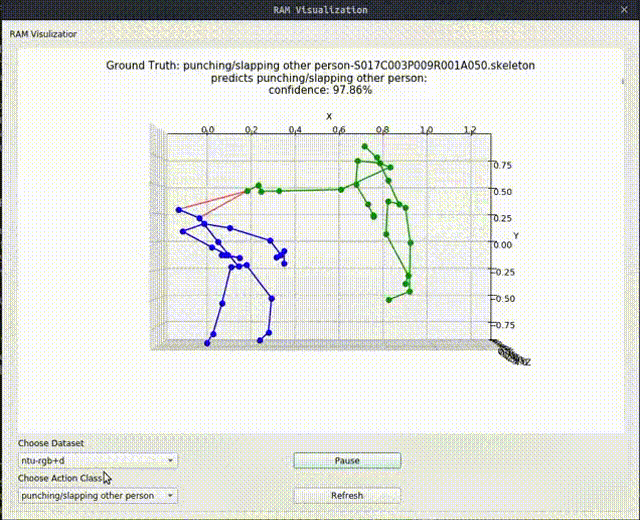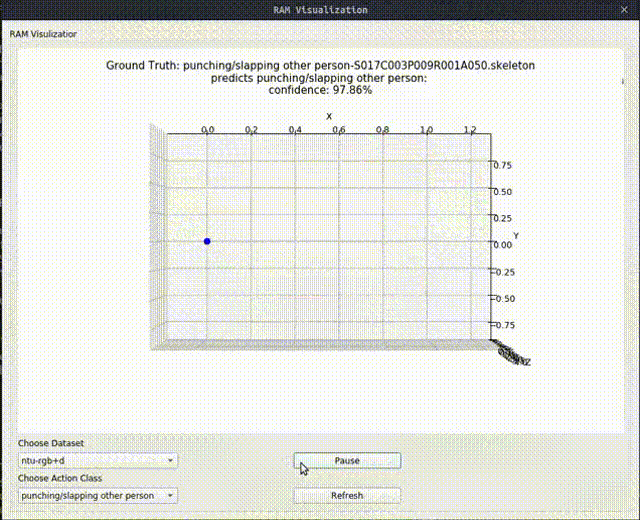
Above image shows one relational graph at a single frame, which is represented by proposed Relational Adjacency Matrix. It is generated separately for each frame of a sequence of frames in the skeleton sequence.

The generation and utilization are the key components of our paper. Briefly speaking, we generate the relational links, or the RAM, which represents the relational links by considering two components. They are the geometric component and the relative attention component. The geometric component is straitforward. If two joints each from one actor are close, then we consider them to be correlated. This simple assumption turns out to be very effective. For the relative attention component, we hope it can capture semantic information and connect joints that are semantically similar. We do this by first encode each joint with spatial-temporal graph convolutional layers and then calculate similarity between each joint pairs. Basing on above two component, we combine them using network-learned param and then we have the RAM.

With the RAM, we propose Dyadic Relational Graph Convolution Block (DR-GCB) that apply dyadic relational graph convolution on the two skeletons to learn relational features. DR-GCB is highly extensible and can be plugged to other networks to improve their performance.
Results
We have done extensive experiments. Results show our network and methods achieve significantly better results comparing with other state-of-the-art methods. They also prove the extensibility of our methods. To review the data, please read our paper.
Below we show some generated relational graphs.
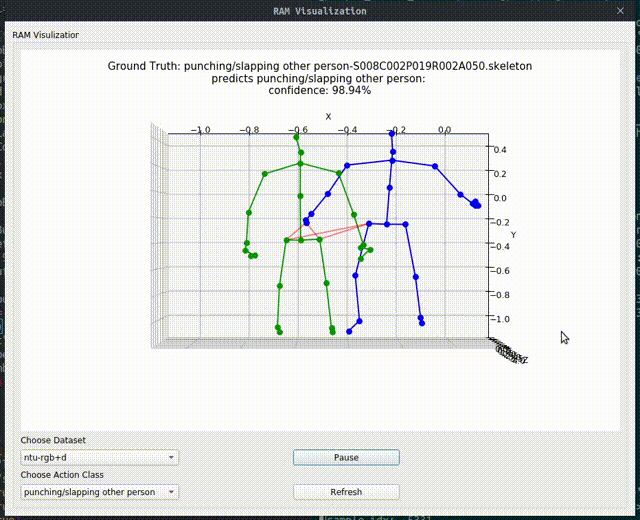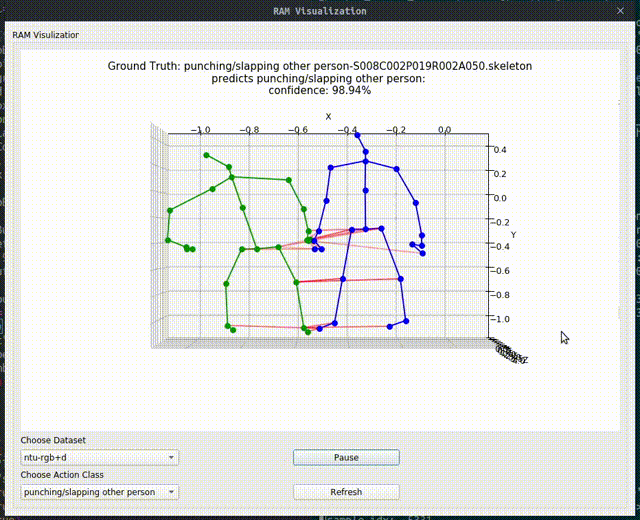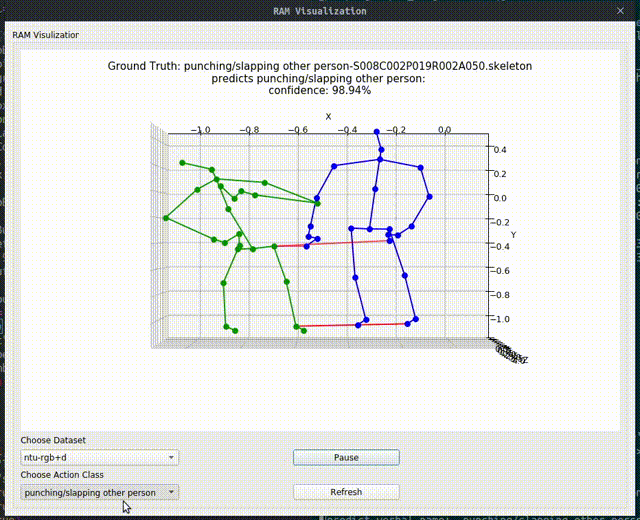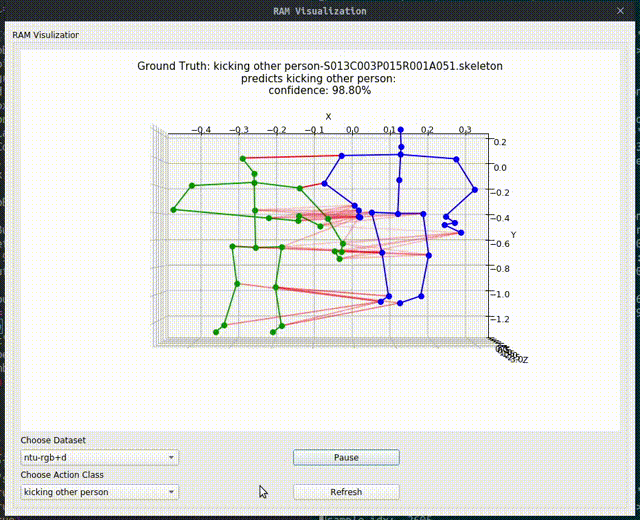
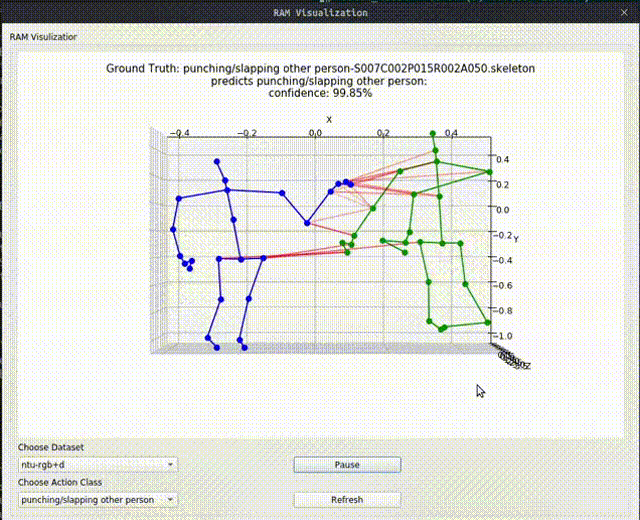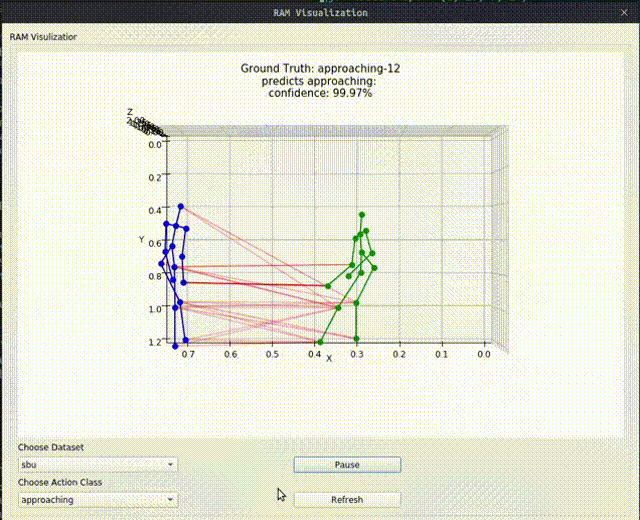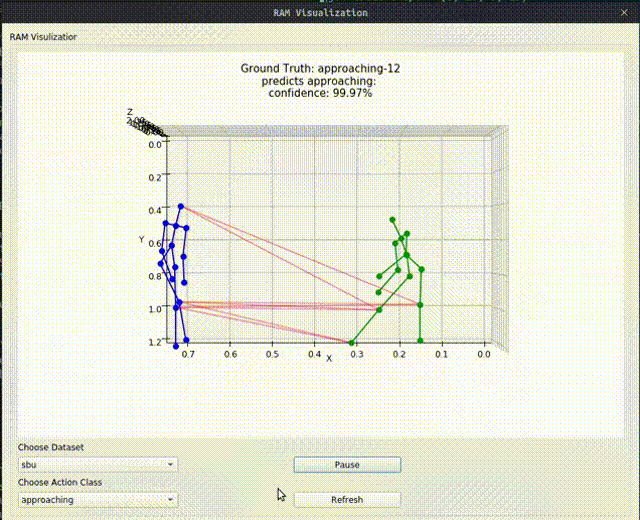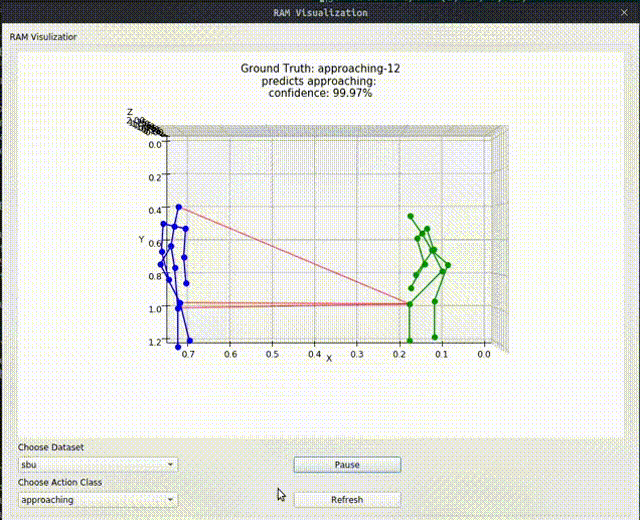
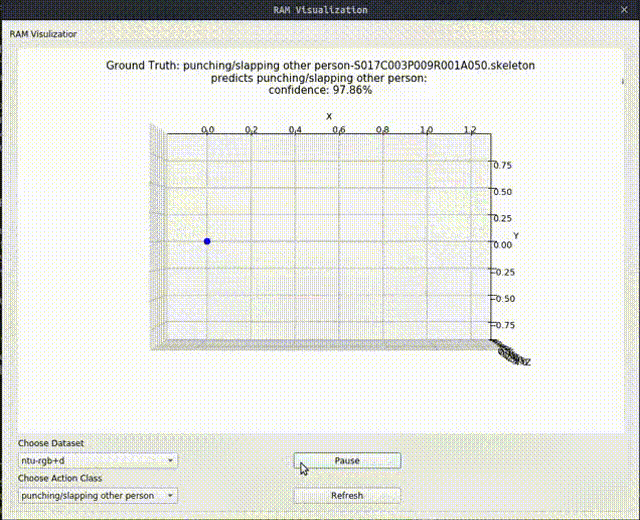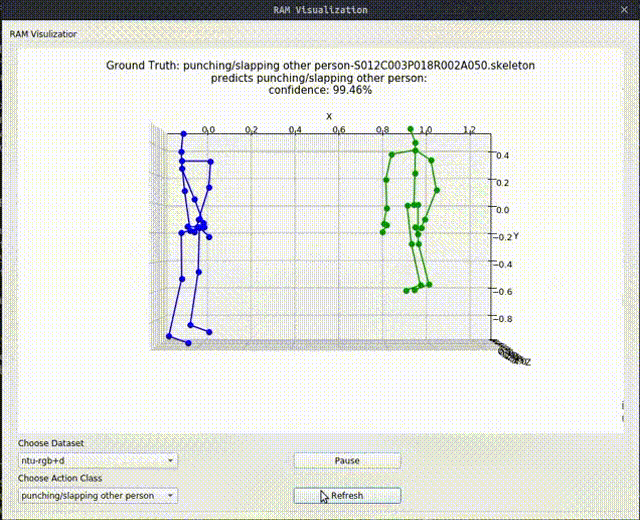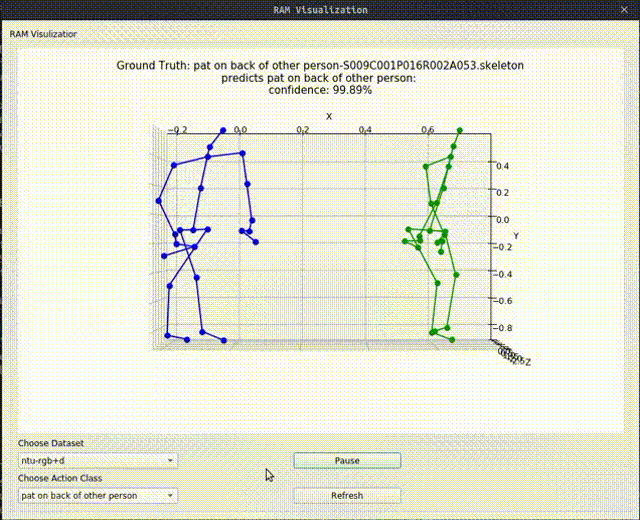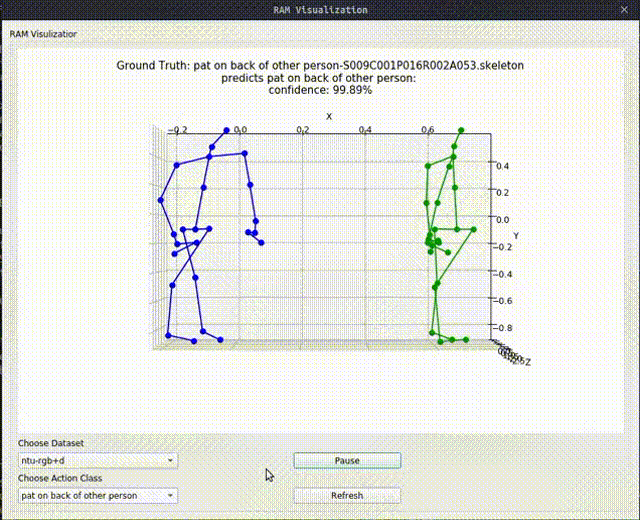
Conclusion
This article is only meant for a brief introduction, if interested please read our paper.
Our paper presents a novel Dyadic Relational Graph Convolutional Network (DR-GCN) for skeleton-based interaction recognition. We devise Relational Adjacency Matrix (RAM) denoting relational graph. It combines both the geometric features and relative attention of the two skeletons in interaction. Dyadic Relational Graph Convolution Block (DR-GCB) is fur- ther proposed to extract spatial-temporal interactive features with RAM. We stack multiple layers of DR-GCBs to build the backbone of our network. We further propose Two-Stream Dyadic Relational AGCN (2S-DRAGCN) that demonstrates our methods’ compatibility with ST-GCN based mod- els. Our proposed models show superior abilities in interaction recognition. They achieve the highest accuracy on the mutual action sub-dataset of NTU- RGB+D, that of NTU-RGB+D 120, and the interaction dataset, SBU.
© 2021. Contents from the accepted version is made available under the CC-BY-NC-ND 4.0 license http://creativecommons.org/licenses/by-nc-nd/4.0/.